




Apache Kafka
Inhaltsverzeichnis
Was ist Apache Kafka?
Apache Kafka ist eine Open-Source Software, die 2011 von dem Sozialen Netzwerk LinkedIn entwickelt wurde und nun zur Apache Software Foundation gehört.
Ursprünglich hat LinkedIn Kafka entwickelt, um 1,4 Milliarden Nachrichten pro Tag zu verarbeiten. Heute wird Apache Kafka von 80% der Fortune 100 Unternehmen eingesetzt, um große Datenströme verarbeiten zu können. Kafka dient dabei als Plattform für die Verarbeitung und Übertragung von Datenströmen in Echtzeit. Diese kann mit anderen Datenökosystemen wie SAP Datasphere verbunden werden.

Wie funktioniert Apache Kafka?
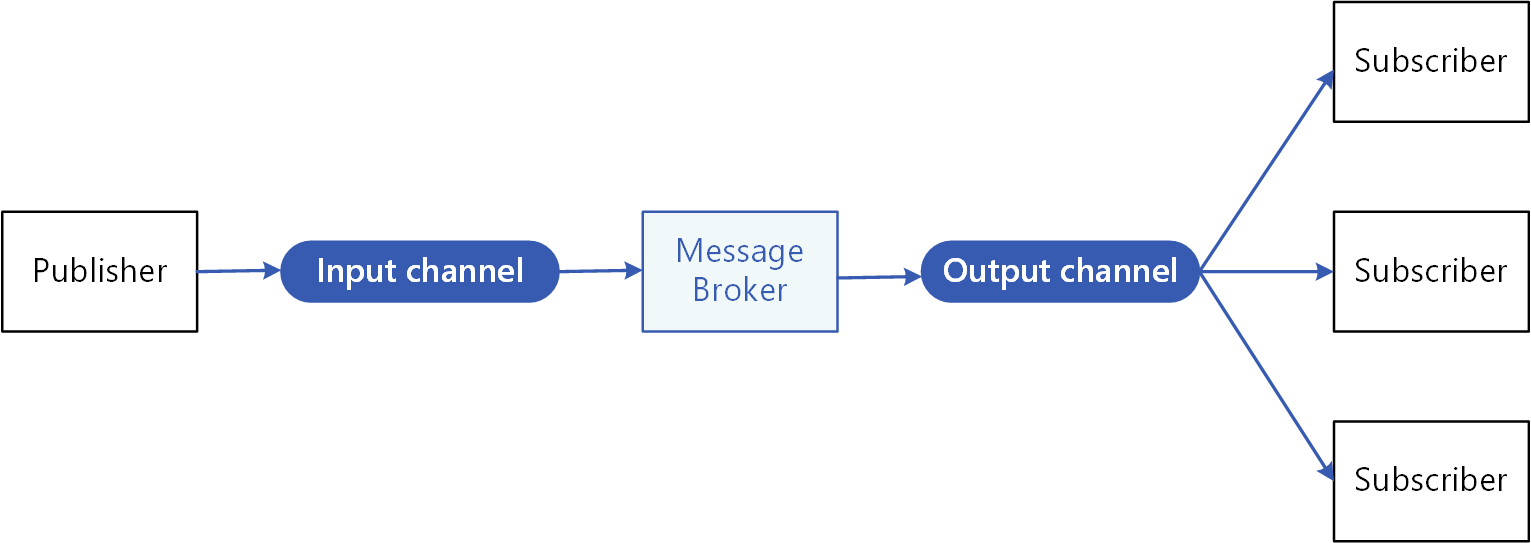
Das Publisher-Subscriber-Modell (Quelle: Microsoft Learn)
Kafka nutzt das Publish-Subscribe-Modell (deutsch: Herausgeber-Abonnenten-Modell), um Nachrichten an Empfänger zu übermitteln. Allerdings werden bei diesem Modell die Nachrichten nicht direkt an den Empfänger übermittelt, sondern zunächst an einen Vermittler, den Message Broker. Die Subscriber können dann die Nachrichten aus dem Broker empfangen. Das Besondere ist, dass die Subscriber auswählen können, welche Nachrichten sie empfangen möchten.
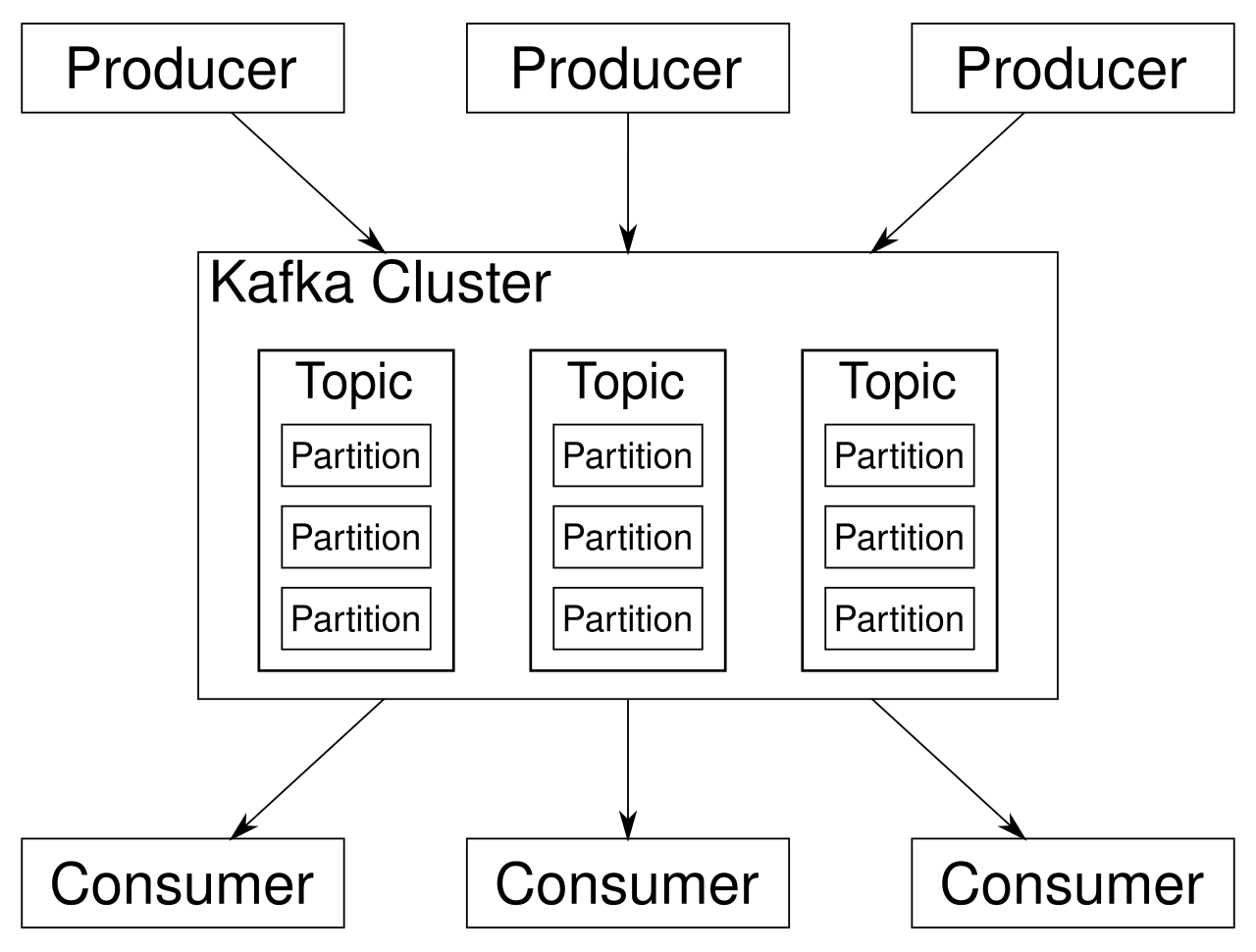
Apache Kafka Schaubild (Quelle: Wikipedia)
Im Kontext von Kafka spricht man von Producern und Consumern. Die Producer übermitteln Informationen an das Kafka Cluster. Dabei geht es um Informationen, bei denen die Reihenfolge eine wichtige Rolle spielt. Diese Informationen werden in den Partitions mit einem Zeitstempel gespeichert. Die Partitions werden zu Topics zusammengefasst, auf die die Consumer zugreifen können. Den Consumern werden die Informationen nun in der richtigen Reihenfolge und in Echtzeit bereitgestellt.
Das folgende Video erklärt die Funktionsweise von Apache Kafka anhand der Berichterstattung in Echtzeit über mehrere Basketballspiele:
Beispiel: Apache Kafka im Unternehmen
Ausgangssituation
Das Unternehmen MediFix GmbH beliefert Krankenhäuser mit Medikamenten und nutzt SAP S/4HANA als ERP-System. Das Unternehmen hat sich auf die Lieferung besonders sensibler Medikamente spezialisiert, die permanent gekühlt werden müssen. Dabei steht es vor zwei Herausforderungen:
- Lückenlose Überwachung der Kühlkette: Die Temperatur der Medikamente muss permanent überprüft werden. Wird bei einer Lieferung die Temperatur der Medikamente überschritten, muss diese Lieferung sofort aussortiert werden.
- Aktuelle Standortinformationen: Der Standort der Lieferfahrzeuge muss für die Krankenhäuser jederzeit verfolgbar sein, um die Lieferungen schnell entgegennehmen zu können.
Apache Kafka hilft bei der Bewältigung dieser Herausforderungen und ermöglicht die Versorgung der MediFix GmbH und der Krankenhäuser mit Echtzeit-Informationen.
Vorgehen
Die MediFix installiert in ihren 10 Lieferfahrzeugen Temperatur- und GPS-Sensoren. Die Sensoren sind die Producer und senden jeweils alle fünf Sekunden eine aktuelle Temperatur und einen Standort an das Kafka-Cluster. Hier gibt es ein Temperatur-Topic und ein Standort-Topic. Die MediFix GmbH ist ein Consumer, der sich für die Temperatur der Lieferung und den Standort der Lieferwagen interessiert.
Die Krankenhäuser vertrauen bezüglich der Temperatur auf die MediFix und interessieren sich deshalb nur für den Standort der Lieferwagen. Die MediFix abonniert also beide Topics, während die Krankenhäuser nur das Standort-Topic abonnieren.
MediFix möchte die Standortinformationen nutzen, um die Routen der Lieferwagen besser planen zu können. Innerhalb des Standort-Topics gibt es 10 Partitions für die 10 Lieferwagen des Unternehmens. So kann MediFix die Informationen über den Standort jeweils für ein spezielles Fahrzeug einsehen. Gäbe es die Partitions nicht, hätte MediFix zwar alle relevanten Informationen über alle Standorte von allen Fahrzeugen, allerdings vollkommen ungeordnet.

Innerhalb einer Partition sind die Informationen über den Standort eines Fahrzeugs in einzelne Pakete aufgeteilt, die jeweils den Standort des Fahrzeugs in einem 5 Sekunden-Intervall anzeigt. Diese Pakete heißen Records. Diese Records müssen in der Partition in der richtigen Reihenfolge geordnet sein, da sonst eine Verfolgung der Route des Fahrzeugs nicht möglich wäre. Der Standort würde sonst quasi hin- und herspringen.
Deshalb versieht Apache Kafka die Records jeweils mit einem Zeitstempel, damit der Consumer sie in der korrekten Reihenfolge lesen kann. Das Gleiche gilt natürlich auch für die Temperatur-Records. Diese müssen ebenfalls in der richtigen Reihenfolge gespeichert werden, um die korrekte Überwachung der Kühlkette zu ermöglichen.
Kafka sorgt also als Vermittler zwischen den Producern (Sensoren) und den Consumern (MediFix und Krankenhäuser) dafür, dass die beiden Consumer jeweils in Echtzeit die für sie relevanten Informationen erhalten.
Weitere Anwendungen
Neben dieser Bereitstellung von Informationen in Echtzeit liegt die besondere Stärke von Apache Kafka in der hohen Skalierbarkeit. So könnte Kafka in der MediFix GmbH auch viele weitere Informationen in Echtzeit bereitstellen wie beispielsweise Liefer- oder Verkehrsdaten. MediFix könnte Apache Kafka in sein Liefersystem integrieren, sodass die Auslieferung und die Menge der Medikamente in den Fahrzeugen in Echtzeit überwacht werden können.
Kafka könnte auch auf aktuelle Verkehrsinformationen zugreifen und sie in Echtzeit an die Logistikabteilung von MediFix übermitteln. Diese könnte dann bei einem aufkommenden Stau eine Alternativroute planen, damit die Medikamente rechtzeitig ankommen.
Kafka arbeitet deshalb so effizient, weil die Echtzeit-Informationen nur an die Consumer übermittelt werden, für die sie relevant sind. Außerdem speichert Kafka die Daten nur so lange wie nötig. So kann MediFix beispielsweise einstellen, dass die Standortdaten nach Beendigung einer Route sofort gelöscht werden, während die Temperaturdaten 30 Tage gespeichert werden, um mögliche gesetzliche Bericht-Vorschriften zu erfüllen.
Vorteile von Apache Kafka
Hohe Skalierbarkeit
Aufgrund der Aufteilung in die Partitions und der effizienten Verteilung der Nachrichten an die passenden Consumer können Unternehmen mit Apache Kafka sehr große Datenmengen verarbeiten. Aus diesem Grund nutzen auch große internationale Unternehmen wie Netflix, PayPal und Uber die Software.
Zuverlässigkeit
Durch die Replikation der Daten auf verschiedene Server ist Kafka eine zuverlässige und wenig fehleranfällige Lösung für die Übermittlung großer Datenmengen.
Flexibilität
Anwendungen wie Kafka Connect oder Kafka Streams erlauben weitere Funktionen wie die Integration von Kafka in andere Systeme und die Entwicklung von neuen Lösungen mit den Vorteilen der Cluster-Architektur.
Ihre Mitarbeiter sind aufgrund ständiger Änderungen im Reporting-Umfeld verwirrt? Nutzen Sie den Managers Update Service.
Confluent als kommerzieller Anbieter von Apache Kafka
Wie das Beispiel zeigt, ist Apache Kafka eine sehr nützliche Software für die Übermittlung von Echtzeit-Daten. Dabei ist Kafka zwar grundsätzlich kostenfrei verfügbar, die Betreuung der Software im Unternehmen selbst ist jedoch sehr aufwendig und erfordert viel Spezialwissen.
Hier schafft das Unternehmen Confluent Abhilfe, indem es Produkte anbietet, die auf Apache Kafka basieren. Confluent kümmert sich um die Betreuung der Software und ermöglicht außerdem erweiterte Funktionen für Kafka wie die Cloud-basierte Lösung Kora.
Zentral ist die Daten-Streaming-Plattform von Confluent mit dem Anspruch, eine cloud-native Erfahrung auch in einer selbstverwalteten Umgebung on-premise zu bieten.
Fazit
Apache Kafka ist weltweit die Standardlösung zur Übermittlung von Echtzeit-Daten. Die besondere Architektur der Software ermöglicht die effiziente Übertragung von Informationen in der richtigen Reihenfolge an die richtigen Empfänger. So haben die Beteiligten die aktuellen Informationen im Blick und können schnell reagieren, wenn Probleme auftauchen.
Wenn Sie sich weiter über Apache Kafka informieren möchten, kontaktieren Sie uns gerne. Wir helfen Ihnen dabei, die Echtzeit-Übermittlung von Daten in Ihrem Unternehmen voranzubringen.
Weitere Informationen
FAQ
Was ist Apache Kafka und wofür wird es verwendet?
Apache Kafka ist eine Open-Source-Software, die von LinkedIn entwickelt wurde und nun zur Apache Software Foundation gehört. Kafka dient als Plattform für die Verarbeitung und Übertragung von Datenströmen in Echtzeit. Zahlreiche Unternehmen nutzen die Software, um große Datenmengen zuverlässig und skalierbar zu verarbeiten.
Wie funktioniert Apache Kafka?
Kafka basiert auf dem Publish-Subscribe-Modell, bei dem Daten nicht direkt an Empfänger übermittelt, sondern über einen Message-Broker verteilt werden. Produzenten (Producer) senden Daten an Kafka-Cluster, wo sie in sogenannten Topics gespeichert und von Konsumenten (Consumer) in der richtigen Reihenfolge abgerufen werden können.
Welche Vorteile bietet Apache Kafka Unternehmen?
Apache Kafka ermöglicht eine skalierbare, zuverlässige und flexible Verarbeitung von Echtzeit-Daten. Es wird branchenübergreifend eingesetzt, um beispielsweise Lieferketten, Transaktionen oder Sensordaten in Echtzeit zu analysieren und darauf zu reagieren. Durch die Cluster-Architektur ist es fehlertolerant und besonders leistungsfähig.
Wer kann mir beim Thema Apache Kafka helfen?
Wenn Sie Unterstützung zum Thema Apache Kafka benötigen, stehen Ihnen die Experten von Compamind, dem auf dieses Thema spezialisierten Team der mindsquare AG, zur Verfügung. Unsere Berater helfen Ihnen, Ihre Fragen zu beantworten, das passende Tool für Ihr Unternehmen zu finden und es optimal einzusetzen. Vereinbaren Sie gern ein unverbindliches Beratungsgespräch, um Ihre spezifischen Anforderungen zu besprechen.








