
Data Lakehouse
Inhaltsverzeichnis
Hintergrund
Der Begriff “Data Lakehouse” ist ein sogenanntes Kofferwort, da er sich aus “Data Lake” und “Data Warehouse” zusammensetzt. Ein Data Lakehouse vereint die Eigenschaften und Vorteile dieser beiden Datenbanken mit dem Ziel, eine fortschrittlichere Datenverwaltungsarchitektur zu schaffen. Daher ist es für ein tieferes Verständnis eines Data Lakehouses hilfreich, sich mit seinen beiden „Grundbausteinen“ auseinanderzusetzen.
Vereinfachung & Effizienz
Das Konzept des Data Lakehouse ist eine Datenspeicherstrategie, welche die Stärken von Data Lakes und Data Warehouses in sich vereint. Es handelt sich um eine Architektur, die eine breite Palette von Datenanalysen zu unterstützt und dabei auf kosteneffektivem Speicher aufbaut.


Im Zentrum dieses Ansatzes steht die Vereinfachung der Datenlandschaft: Statt separate Systeme für unterschiedliche Datenformate und -analysen zu unterhalten, konzentriert sich ein Data Lakehouse darauf, alles unter einem Dach anzubieten. Die Arbeit mit Daten wird dadurch effizienter. Datenprofis müssen nicht mehr zwischen verschiedenen Speicherorten wechseln, um Zugang zu den benötigten Informationen zu erhalten. Über ein Data Lakehouse können die Teams immer auf die aktuellsten Daten zugreifen, die für Aufgaben in den Bereichen Data Science, Machine Learning und Business Analytics erforderlich sind.
Funktionen
Das Fundament eines Data Lakehouse bildet eine Metadatenschicht, die auf offenen Dateiformaten wie Parquet basiert. Es überträgt wesentliche Eigenschaften eines Data Warehouse auf den kostengünstigeren Speicher eines Data Lake. Diese Schicht verwaltet Informationen darüber, welche Dateien zu welchen Tabellenversionen gehören unterstützt fortgeschrittene Funktionen wie ACID-konforme Transaktionen.
Verbesserungen in der Technologie, insbesondere bei den Abfrage-Engines, haben die effiziente Ausführung von SQL-Abfragen auf einem Data Lake ermöglicht. Diese Optimierungen ermöglichen es, häufig abgerufene Daten im RAM oder auf SSDs zwischenzuspeichern und in effizientere Formate zu konvertieren. Darüber hinaus profitieren Data Lakehouses von Optimierungen wie datenlayout-basiertem Clustering. Es beschleunigt den Zugriff auf gemeinsam genutzte Datensätze. Auch die Optimierung von Abfragen verläuft durch unterstützende Datenstrukturen wie Statistiken und Indizes flüssiger. Moderne CPUs tragen durch vektorisierte Verarbeitung ebenfalls zur Leistungssteigerung bei.
Dank offener Datenformate können Data Scientists und Machine-Learning-Ingenieure problemlos auf die Daten im Lakehouse zugreifen und mit gängigen Tools aus dem Data Science- und Machine-Learning-Ökosystem arbeiten.
Zusätzliche Funktionen wie ein Audit-Verlauf und die Möglichkeit, durch Datenversionen zu reisen, erhöhen die Nachvollziehbarkeit und Reproduzierbarkeit in der Datenanalyse. Darüber hinaus sind sie auch im Bereich des maschinellen Lernens förderlich.
Data Lakehouse im Vergleich
Ein Data Lakehouse vereint die Eigenschaften und Vorteile von Data Warehouse und Data Lakes, um eine fortschrittliche Datenverwaltungsarchitektur zu schaffen. Durch die umfassende Datenspeicherung des Data Lakes sowie fortgeschrittener Verwaltungs- und Analysefunktionen des Data Warehouse soll das Lakehouse optimale Datenverfügbarkeit und Leistung bieten. Es verbindet die Speicherkapazitäten eines Data Lakes für große Mengen verschiedener Datenformate mit den Management- und Analysetools eines Data Warehouse. Darunter fallen auch Business Intelligence, Machine Learning und ACID-Transaktionen für Datenintegrität.
Das Data Lakehouse ermöglicht eine konsistente und zuverlässige Datennutzung. Es vereint den einfachen Datenzugang eines Data Warehouses mit der flexiblen, kosteneffizienten Datenhaltung eines Data Lakes. Es erleichtert den Zugriff und die Nutzung von Daten durch ein integriertes System, das eine konsistente und umfassendere Datenansicht ermöglicht, die die Analyse von Daten verbessert und datenbasierte Entscheidungen unterstützt.
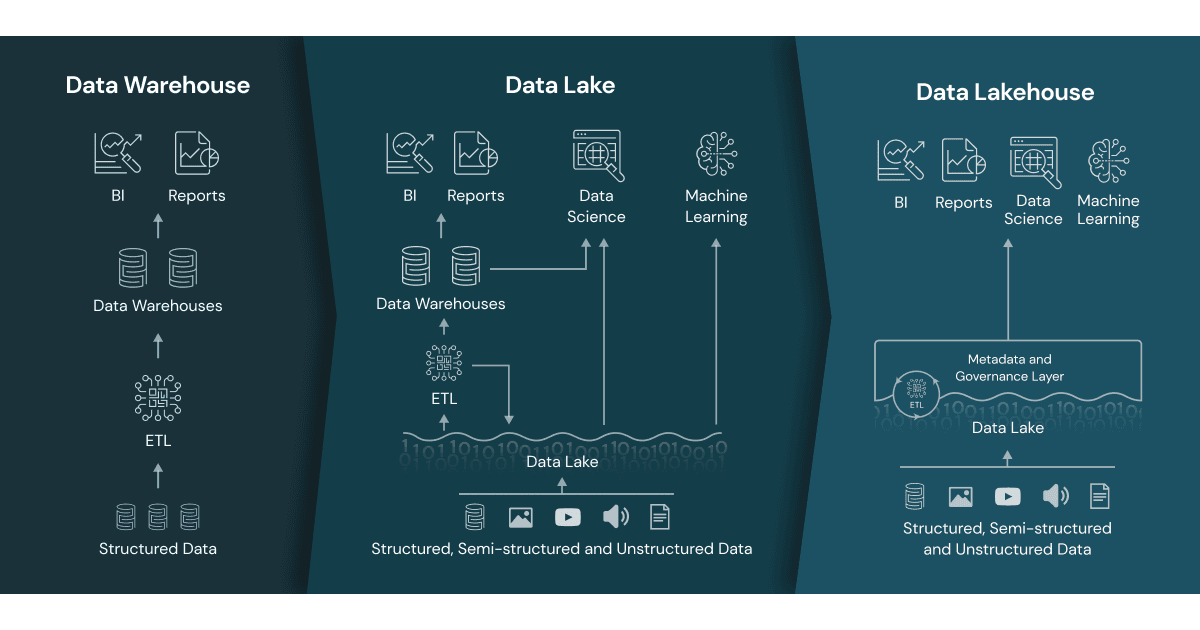
Quelle: databrick.com
Vor- und Nachteile
Vorteile
- Kombinierte Funktionalität: Vereint die Flexibilität und Kosteneffizienz von Data Lakes mit den Datenverwaltungsfunktionen und ACID-Transaktionen von Data Warehouse.
- Effizienzsteigerung: Beschleunigt die Arbeit der Datenteams durch die Zusammenführung in ein einziges System, wodurch Daten ohne Abfrage mehrerer Systeme genutzt werden können.
- Aktuelle und vollständige Daten: Stellt sicher, dass den Teams stets die neuesten und umfassendsten Daten für Data Science, maschinelles Lernen und Business Analytics zur Verfügung stehen.
Nachteile
- Komplexität in der Einrichtung und Verwaltung: Die Integration von Funktionalitäten aus Data Lakes und Data Warehouse kann zu komplexeren Systemen führen, die anspruchsvoller in Einrichtung und Management sind.
- Potenzielle Leistungseinbußen: Die Kombination zweier Systeme kann, abhängig von der Implementierung, zu suboptimalen Leistungsergebnissen in bestimmten Anwendungsfällen führen.
- Mangelnde Reife: Da es sich um ein relativ neues Konzept handelt, könnte das Data Lakehouse in einigen Aspekten weniger ausgereift sein und noch nicht die Stabilität traditioneller Systeme erreicht haben.
Fazit
Das Data Lakehouse vereint die Stärken von Data Warehouse und Data Lakes, um einen fortschrittlichen Ansatz im Datenmanagement zu bieten. Während sich Data Warehouses auf strukturierte historische Daten spezialisieren und bei großen Datenmengen kostspielig sein können, bieten Data Lakes Flexibilität und Kosteneffizienz für diverse Datenformate, bergen jedoch Organisationsrisiken. Das Lakehouse-Modell bietet in einer vereinheitlichten Architektur Speicherkapazitäten sowie Verwaltungs- und Analysefunktionen. Dabei werden komplexe Herausforderungen adressiert. Obwohl das Modell in Bezug auf Komplexität und Reife noch Entwicklungspotenzial aufweist, stellt es eine zukunftsträchtige Lösung für datenbasierte Entscheidungen und Analysen dar.
FAQs
Was ist ein Data Lakehouse?
Ein Data Lakehouse ist eine fortschrittliche Datenverwaltungsarchitektur, die die Flexibilität und Kosteneffizienz von Data Lakes mit den robusten Datenverwaltungsfunktionen und der Datenintegrität von Data Warehouses kombiniert. Es ermöglicht eine umfassendere und effizientere Datenanalyse durch die Integration offener Dateiformate und fortschrittlicher Funktionen wie ACID-konformen Transaktionen.
Warum ein Data Lakehouse?
Der Einsatz eines Data Lakehouse bietet Unternehmen eine vereinfachte, leistungsstarke Datenlandschaft, die eine breite Palette von Datenanalysen unterstützt. Es kombiniert die umfangreiche Speicherfähigkeit von Data Lakes für verschiedene Datenformate mit den analytischen und Managementfunktionen eines Data Warehouse. Dies steigert die Effizienz, indem es einen einheitlichen Zugriff auf aktuelle und vollständige Daten für Bereiche wie Data Science, Machine Learning und Business Analytics bietet.
Was ist ein Data Warehouse?
Ein Data Warehouse speichert und analysiert große Mengen historischer Unternehmensdaten, unterstützt dabei strategische Entscheidungen. Nachteile können hohe Betriebskosten und begrenzte Flexibilität bei unstrukturierten Daten sein.
Was ist ein Data Lake?
Ein Data Lake ist eine umfangreiche Speicherlösung für diverse Rohdatenarten, von unstrukturiert bis strukturiert. Er bietet Flexibilität in der Datenspeicherung, ist essenziell für Big-Data-Anwendungen, birgt jedoch das Risiko unorganisierter Datenansammlungen, sogenannter „Data Swamps“.
Wer kann mir beim Thema Data Lakehouse helfen?
Wenn Sie Unterstützung zum Thema Data Lakehouse benötigen, stehen Ihnen die Experten von Compamind, dem auf dieses Thema spezialisierten Team der mindsquare AG, zur Verfügung. Unsere Berater helfen Ihnen, Ihre Fragen zu beantworten, das passende Tool für Ihr Unternehmen zu finden und es optimal einzusetzen. Vereinbaren Sie gern ein unverbindliches Beratungsgespräch, um Ihre spezifischen Anforderungen zu besprechen.






